
O tema “Inteligência Artificial” atingiu o seu ápice de popularidade em 2023. O assunto deixou de ser restrito aos especializados círculos acadêmicos para ser casualmente discutido nos mais variados grupos e nas mais triviais situações do dia a dia.
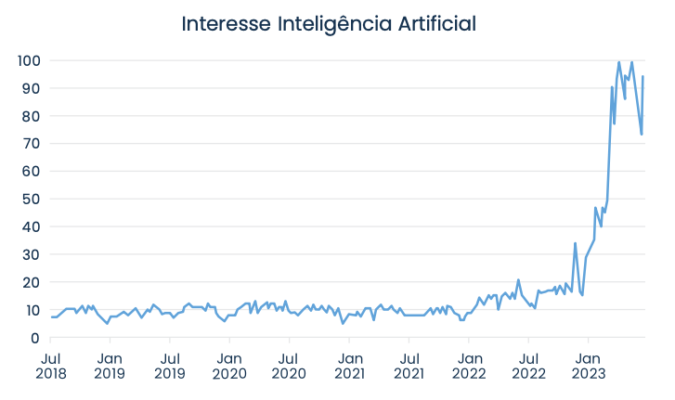
Esse rápido aumento de interesse decorreu da democratização inédita do acesso às técnicas de inteligência artificial. A população foi exposta pela “primeira vez” às capacidades desse tipo de ferramenta, através de aplicativos como o ChatGPT, Midjourney, Dall-e e outros. Coloco “primeira vez” em aspas porque, apesar da sensação de novidade, essa certamente não foi a primeira exposição que tiveram – qualquer um que já usou o Google, Netflix ou alguma rede social já teve contato com esse tipo de tecnologia. Essa foi, entretanto, a primeira vez que usaram esse tipo de ferramenta de forma consciente e ativa. Apesar da popularidade recente, esse tema não é, sob nenhuma hipótese, algo novo. A primeira rede neural (uma das ferramentas que pode constituir um sistema de inteligência artificial) foi programada em circuitos elétricos em 1943, muitas décadas antes da criação do primeiro computador pessoal. Assim, a novidade não é a tecnologia em si – essa já existe há 80 anos – mas sim a democratização do acesso a ela.
A expressão inteligência artificial traz consigo uma boa dose de mística: para muita gente aparenta ser um “ser” consciente capaz de pensar e resolver problemas, assim como uma pessoa faria. Verdade seja dita, a palavra “inteligência” empregada no termo contribui para essa visão fantasiosa. Na realidade, a tecnologia está distante desse ideal de inteligência, ainda que seja muito eficiente para resolver alguns tipos de problemas.
As primeiras inteligências artificiais nasceram para resolver problemas que a computação tradicional não era capaz. Até então, toda programação tinha uma sequência bem definida de passos a serem seguidos, com a finalidade de resolver um problema fechado e específico. Essa abordagem não funciona quando o objetivo é entregar respostas personalizadas (pense em um algoritmo de recomendações como o do Netflix, por exemplo) ou para incorporar informações novas ao longo do tempo (como o Google). Para essas situações, surgiu a ideia de um algoritmo – ou mais popularmente, uma máquina – que fosse capaz de aprender com os dados. Essa é a raiz de todo o campo da inteligência artificial.
Durante a história do desenvolvimento do aprendizado de máquinas, assim como em qualquer outro processo de inovação, surgiram divergências. Grupos de pesquisa começaram a se formar, cada qual com suas técnicas, metodologias e, sobretudo, inspirações distintas. Os chamados Simbolistas se inspiraram no encadeamento de ideias de forma lógica para chegar ao aprendizado, os Conexionistas buscaram emular as conexões cerebrais e as sinapses que ocorrem dentro do cérebro humano, os Evolucionistas usaram a Teoria da Evolução de Darwin para gerar aprendizado a partir de mutações ao longo de várias gerações de algoritmos, os Bayesians partiram da estatística e da probabilidade e, por fim, os Analogistas buscaram o aprendizado de máquina através da similaridade entre as diferentes situações.
Cada uma dessas abordagens é mais adequada para resolver um tipo de problema – e ineficiente para resolver outros.
A seguir, exploraremos as características de cada uma dessas 5 “tribos”, abordando quais foram suas inspirações e quais problemas conseguem resolver de forma mais eficiente.
Os Simbolistas – O aprendizado vem da lógica
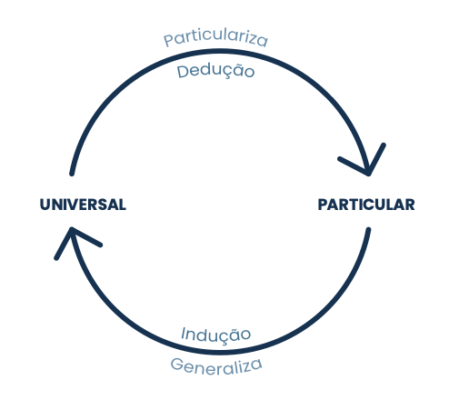
Começaremos pela abordagem dos Simbolistas, que foi a primeira a surgir nos círculos acadêmicos. Esse grupo buscou no processo lógico a inspiração para criar algoritmos de aprendizagem. Mais especificamente, utilizam o processo de indução (ou dedução reversa) para obter regras generalizadas a partir de fatos específicos.
Vamos por partes. De acordo com os Simbolistas, os seres humanos aprendem segundo o processo de dedução. A dedução parte de realidades abrangentes para chegar a realidades particulares sobre determinado assunto. Por exemplo: se sabemos que Sócrates é um humano e sabemos que humanos são mortais, logo podemos deduzir que Sócrates é mortal.
Note que, nesse caso, partimos de uma regra geral (todos os humanos são mortais) para chegarmos a uma particularidade (Sócrates é mortal).
O processo de indução segue o caminho contrário: partimos de várias realidades específicas e particulares para criar uma regra geral. Nesse caso, sabemos que Sócrates é humano e sabemos que ele é mortal. Sabemos também que Aristóteles é humano e também mortal. Platão também. Nesse caso, podemos inferir a regra geral de que todos os humanos são mortais.
Essa é a lógica usada pelos Simbolistas. Ao treinar um algoritmo em uma base de dados extensa, este algoritmo busca padrões de comportamento que se repetem para aprender regras abrangentes
Um exemplo de aplicação dessa ideia são os Large Language Models (LLM), categoria na qual se encaixa o ChatGPT. Esse sistema criado pela OpenAI foi treinado em uma base gigantesca de textos (para fins práticos, tudo o que está escrito na internet) buscando padrões e generalizando esses padrões em regras abrangentes. Esse é o “conhecimento” usado em cada resposta oferecida pelo programa aos seus usuários.
Claro que, assim como em todo modelo matemático, o output é completamente dependente do input. Dito de outra forma, caso haja informações erradas na base usada para treinamento – você diria que tem informações erradas escritas na internet? -, os aprendizados do modelo serão igualmente errados. É o famoso “Junk in, Junk out” (Se entra lixo, sai lixo). Essa é, entretanto, uma discussão para um próximo artigo.
Os Conexionistas – O cérebro humano como inspiração
Que melhor exemplo de aprendizagem poderíamos escolher do que o próprio cérebro humano? Mais especificamente, será que é possível emular as conexões e sinapses que ocorrem entre os neurônios, que disparam pulsos elétricos de forma sequencial para construir memórias e, por consequência, conhecimento?
Essa é a abordagem dos Conexionistas. Esse grupo utiliza algoritmos chamados de redes neurais para simular os processos internos do cérebro humano. Esses algoritmos são constituídos por várias camadas de nódulos (que seriam equivalentes aos neurônios). Esses nódulos recebem um input, o modificam de alguma forma – cada nódulo representa uma função matemática – e o enviam para a próxima camada. Esse processo ocorre até chegarmos a um output final da rede.
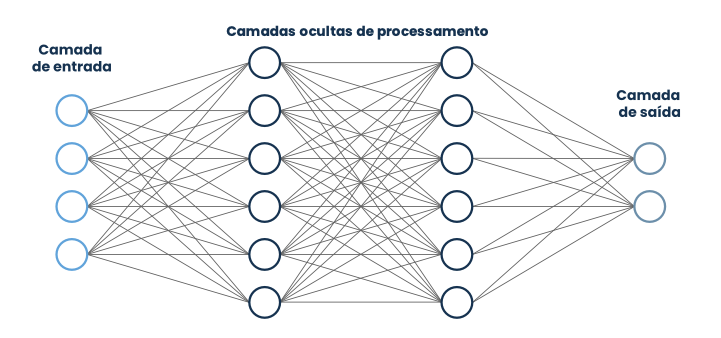
Assim como no cérebro, o segredo desse processo está na conexão entre os neurônios (sinapses). Quanto mais forte a conexão, maior o peso deles na decisão final. Essas redes são treinadas por um processo chamado backpropagation, no qual o output é comparado com a resposta real esperada e, caso haja diferença, esse erro é propagado desde o final da rede, voltando cada camada – calibrando nesse processo a intensidade da conexão entre os nódulos, mudando assim o peso de cada nódulo na decisão final – até os primeiros nódulos. Esse processo se repete inúmeras vezes até o output da rede coincidir com a resposta real do problema a ser resolvido.
Essa abordagem já mostrou sucesso em diversos campos, com destaque para os que usam dados não estruturados, como é o caso das classificações e diagnósticos de doenças por exames de imagem, reconhecimento facial e processamento de linguagem natural (tanto em textos quanto em áudio).
Os Evolucionistas – Darwin tem a resposta
Os Evolucionistas encontraram o seu Santo Graal em um lugar completamente diferente dos seus pares. Para eles, a Teoria da Evolução de Darwin esconde a forma mais eficiente de aprendizado: mutações ocorrem de geração para geração e o processo de seleção natural das espécies elimina as mutações ineficientes, enquanto perpetua mutações positivas, que serão propagadas para as próximas gerações.
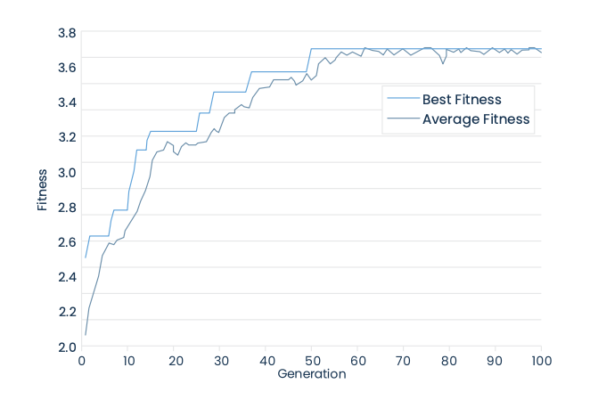
Sendo assim, são criados diversos algoritmos aleatórios, que são testados segundo sua capacidade de resolver determinado problema. Os que se saírem pior nessa tarefa são descartados. Os que se saírem melhores (ainda que sejam muito ruins) tem suas características combinadas (simulando o processo natural de cruzamento das espécies) e sofrem alguma mutação randômica. Assim nasce a segunda geração, que passará pelo mesmo processo gerando uma terceira, uma quarta, uma quinta geração e assim por diante.
Essa abordagem “genética” resulta, após inúmeras gerações, em algoritmos que são capazes de resolver o problema proposto com um nível de eficiência muito maior do que seus pais de gerações anteriores.
Uma das aplicações mais interessantes – e talvez assustadoras – do trabalho dos Evolucionistas é o campo que estimula a evolução de robôs no mundo real. Na pesquisa e desenvolvimento do Laboratório Hod Lipson (Columbia University), os robôs começam como combinações aleatórias de peças, ainda como projetos dentro dos softwares dos pesquisadores, e milhares de rodadas de testes e novas gerações acontecem. Quando o processo resulta em uma geração evoluída o suficiente, estes robôs são impressos em impressoras 3D e os testes passam a ser conduzidos no mundo real. Os robôs são avaliados por sua capacidade de andar, navegar dentro de túneis, escalar, etc. Toda nova geração de robôs é encarregada de programar a impressora 3D que vai imprimir seus sucessores.
Uma característica interessante desse tipo de abordagem é a natureza mais “visual” do processo de evolução dos algoritmos – pelo menos quando comparada às outras abordagens. Talvez seja a que deixe mais clara a melhoria atingida a cada nova geração. Deixo aqui o link para o vídeo dos testes do Mar.io, um outro projeto de algoritmo genético, criado com o intuito de jogar uma fase do jogo “Super Mario Bross”, que mostra essa evolução.
Os Bayesianos – Tudo é uma questão de probabilidade
Os Bayesians carregam a fama de serem a tribo mais fanática de todas. Eles têm uma devoção semi-dogmática aos seus paradigmas estatísticos, especialmente ao Teorema de Bayes, do qual a tribo deriva seu nome.
Para eles, todo aprendizado é necessariamente acompanhado de incerteza – é impossível afirmar algo com 100% de convicção. Por isso, para se aprender, é necessário formular hipóteses, calcular a probabilidade de acerto destas hipóteses e constantemente atualizar esta probabilidade, de acordo com novas observações.
Esses cálculos são feitos com base no Teorema de Bayes, que é possivelmente a fórmula mais importante da probabilidade. Esse teorema descreve como calcular continuamente a probabilidade de um evento, tendo em vista novas evidências.
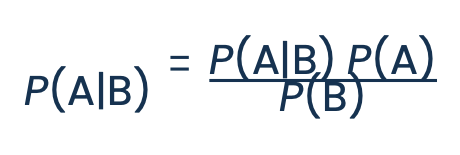
Uma maneira simples de entender o Teorema é por meio do problema do nascer do sol, desenvolvido por Pierre-Simon Laplace: qual é a probabilidade do sol nascer amanhã?
Esta pergunta parece trivial. No entanto, se não tivéssemos nenhum conhecimento prévio sobre o Sol – se não soubéssemos nada sobre astrofísica, ou sobre a rotação da Terra – a única forma de calcular a probabilidade dele nascer amanhã seria por meio da quantidade de dias que já o observamos nascer no passado. No primeiro dia (quando ainda não temos nenhuma observação, a probabilidade do sol nascer seria 50%. A cada dia que passa (e o Sol nasce), a probabilidade de que ele nascerá novamente no dia seguinte se torna maior, se aproximando (mas nunca chegando) ao 100%.
O trabalho dos Bayesianos tem aplicações em diversas áreas, sendo que uma delas já faz parte do nosso dia a dia há décadas: os filtros de Spam. O funcionamento é simples. Antes de ter acesso aos e-mails, o filtro cria duas hipóteses: (1) o e-mail é spam ou (2) o e-mail não é spam. A probabilidade prévia das hipóteses é baseada em uma estimativa do total de spam dentro do total de e-mails – pelo menos 90% de todos os e-mails são spam.
A evidência que vai atualizar a probabilidade das hipóteses é o conteúdo do e-mail. Se o e-mail contém a palavra “Promoção”, por exemplo, a probabilidade de ser spam é grande. Se contém a palavra “GRÁTIS”, a probabilidade é ainda maior. Se a palavra “GRÁTIS” for acompanhada de quatro pontos de exclamação, a probabilidade de ser spam é praticamente 100%.
No entanto, se o e-mail contém o nome de uma pessoa próxima a você, a probabilidade de ser spam é reduzida. O filtro analisa cada uma das palavras do e-mail, atualiza a probabilidade de ser spam para cada palavra analisada, e direciona o e-mail para a lixeira se a probabilidade final for alta. Caso contrário, o e-mail é direcionado para o usuário.
Deixo aqui o link para um vídeo do canal Veritasium no Youtube, que explica de forma bastante intuitiva o teorema de Bayes. Adicionalmente, caso você tenha mais facilidade em aprender de forma visual, dê uma olhada nesse vídeo do 3Blue1Brown.
Os Analogistas – Parábolas e Analogias
Por fim, temos o grupo dos Analogistas, que tiraram sua inspiração do aprendizado dos seres humanos com o uso de parábolas e analogias. A ideia central é usar o aprendizado de determinada situação em outras situações, que apesar de diferentes, possuem similaridades.
Essa abordagem busca agrupar os dados segundo sua similaridade e usar as informações de um indivíduo dentro do grupo para inferir informações desconhecidas de outros participantes do mesmo grupo.
Um exemplo muito eficiente de uso dessa ideia é o algoritmo de recomendações do Netflix. Suponha que você tenha dado likes nos filmes Titanic e Interstelar e dislike no filme Homem Aranha. O algoritmo irá buscar outras pessoas que reagiram da mesma forma ao assistirem esses filmes para te oferecer uma recomendação. Suponha que uma outra pessoa tenha julgado esses filmes da mesma maneira (like, like, dislike, respectivamente) e também tenha dado like no filme Laranja Mecânica. Por atribuir uma similaridade entre você e essa outra pessoa, o algoritmo te recomendará o filme Laranja Mecânica.
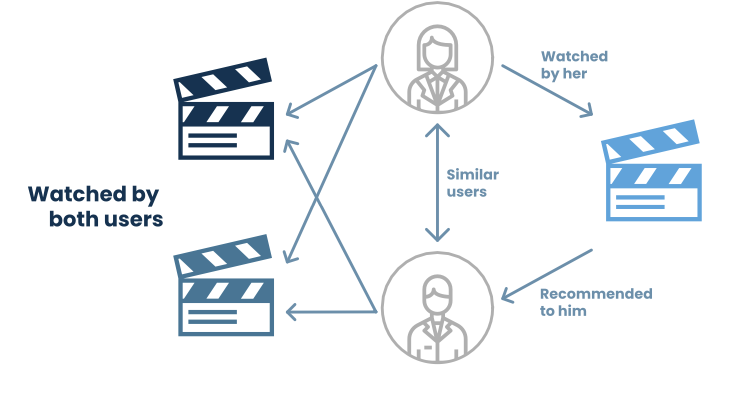
O melhor uso da abordagem dos Analogistas está na solução de problemas complexos ou mal definidos, nos quais a resposta não necessariamente é fechada (certo ou errado), mas há um grau de subjetividade que contribui para a precisão do modelo.
O que fazer com isso?
O objetivo desse artigo é jogar um pouco de luz na concepção geral que a maior parte das pessoas têm sobre o tema Inteligência Artificial. Da forma como é tratada hoje, parece que A.I é uma massa disforme de conceitos abstratos apontando para uma suposta “Inteligência”, o que não contribui em nada para o entendimento do conceito, e nem para o melhor uso de cada uma das ferramentas disponíveis.
Como acabamos de explorar, o objetivo desse tipo de técnica é atacar problemas abertos de forma a incorporar informações novas, o que pode ser entendido pela ideia de aprendizado. Nesse sentido, foram encontradas diversas formas de aprendizado que podem ser usadas, cada qual mostrando bons resultados para algumas tarefas, e resultados não tão bons em outras. Pense no resultado de usar o ChatGPT para uma recomendação de filme: a resposta que você terá será um filme considerado bom por grande parte das pessoas (o que não é necessariamente ruim), mas não uma recomendação específica para você como indivíduo, levando em consideração seus gostos e preferências pessoais – assim como o algoritmo do Netflix foi desenhado para fazer.
Essa distinção entre abordagens se assemelha ao uso de diferentes instrumentos musicais na composição de uma música. Alguns instrumentos são mais generalistas, como o teclado por exemplo, e servem para tocar músicas dos mais diferentes tipos. Alguns têm personalidade um pouco mais fortes, como os instrumentos de sopro, sendo perfeitos para alguns tipos de músicas, enquanto causam estranheza em outros. Esse é um excelente paralelo para as diferentes abordagens de aprendizado de máquina. Cada abordagem pode ser entendida como um tipo de instrumento musical, que desempenha um papel diferente na composição de uma sinfonia.
Dando um passo além, algumas sinfonias mais complexas podem requerer mais de um tipo de instrumento. Nesse caso, mesclar formas de aprendizado em uma abordagem única tem um potencial maior na solução de alguns tipos de problema. Esse é o caso de alguns dos sistemas de inteligência artificial em uso atualmente, como os sistemas de carros autônomos e até mesmo o próprio ChatGPT, que apesar de se encaixar bem na abordagem dos simbolistas, também utiliza redes neurais em sua arquitetura. Esse também é o caso de alguns dos modelos que usamos nos fundos da Giant.
O assunto inteligência artificial é um campo de estudos amplo com enorme potencial. Entretanto, para colher bons frutos dessas ferramentas, três fatores são imprescindíveis: o primeiro é uma alta profundidade acadêmica – necessária para dominar toda a teoria por trás dessas diferentes abordagens, o segundo é a disposição de grande poder computacional – indispensável pela própria natureza desse tipo de algoritmo , e o terceiro é o tempo – necessário para dominar a prática, que normalmente é muito mais complexa do que a própria teoria e requer uma boa dose de “tentativa e erro”.
Na Giant, iniciamos nossos testes no campo da inteligência artificial em 2013. De lá pra cá, tivemos algumas grandes evoluções e descobertas, porém acompanhadas de um número significativamente maior de decepções. Após quase uma década, alguns dos principais modelos dos fundos são frutos do extenso trabalho de pesquisa que desenvolvemos nessa área.
A recente democratização do uso de inteligência artificial e a disseminação do entendimento sobre essas diferentes ferramentas formam um solo muito fértil para inovação e rápida evolução nesse campo. Estamos bastante animados com o prospecto do surgimento de novas tecnologias nesses próximos anos, que poderão ser incorporadas nos nossos modelos trazendo cada vez mais resultado para nossos cotistas.
Fonte:
DOMINGOS, P. The Master Algorithm: How the Quest for the Ultimate Learning Machine Will. Remake our World. New York: Basic Books, 2015